


Di recente si è cimita la RAM di uno dei nodi Proxmox 8 con Ceph del mio cluster casalingo.
Me ne sono accorto perché i servizi ceph-osd@ e ceph-mon@ fallivano e non era possibile riavviarli.
Nei logs erano presenti diverse Segmentation Faults e perciò ho deciso di effettuare dei test sulle memorie tramite MemTester che hanno confermato che un chip di una RAM era mal funzionante.
Ho sostituito la RAM difettosa e ho reinstallato in monitor e l’OSD sul nodo, infine il cluster ha ripreso a funzionare regolarmente.
IDENTIFICARE IL PROBLEMA
Tramite i seguenti comandi è possibile verificare i logs nel journal di systemd dei servizi Ceph falliti:
|
0 1 |
journalctl -xeu ceph-osd@*.service journalctl -xeu ceph-mon@*.service |
Verificare se sono presenti degli errori che potrebbero indicare la corruzione di rocksdb.
Tramite il seguente comando è possibile visualizzare i logs del kernel:
|
0 |
dmesg |
Verificare se sono presenti degli errori simili ai seguenti:
|
0 1 2 |
[ 2114.575583] ceph[18054]: segfault at f10095a9f8 ip 0000000000517c44 sp 00007ffeb3b04350 error 4 in python3.11[41f000+2b5000] likely on CPU 3 (core 3, socket 0) [ 2114.575602] Code: 48 83 ec 18 4c 8b 6f 10 4d 85 ed 0f 8e 45 05 00 00 48 bb c5 67 56 16 2f eb d4 27 49 89 ff 45 31 e4 4b 8b 6c e7 18 4c 8b 75 08 <49> 8b 46 78 48 85 c0 0f 84 2f 33 f1 ff 48 3d c0 e6 4f 00 0f 85 a3 1505589460992 bytes (1.5 TB, 1.4 TiB) copied, 951 s, 1.6 GB/s [ 2964.412919] perf: interrupt took too long (2503 > 2500), lowering kernel.perf_event_max_sample_rate to 79000 |
Se non sono presenti errori di tipo Segmentation Fault è possibile verificare se sono presenti errori relativi all’IO del disco con l’OSD di Ceph fallito.
Se si dovessero riscontrare degli errori di IO, è possibile seguire questa guida per rimuovere l’OSD ed in seguito provare a verificare tramite delle scritture sul disco se si riscontrano ulteriori errori.
Anche l’utility smartctl può essere di aiuto per diagnosisticare dei problemi di disco.
EFFETTUARE DEI TEST ALLA MEMORIA
Se sono stati riscontrati degli errori di tipo Segmentation Fault nei logs, effettuare dei test della memoria per identificare quale RAM è difettosa, in seguito rimoverla o sostituirla.
Prima di riavviare il nodo, si consiglia aggiornale l’immagine initramfs, poiché è possibile essa che sia inconsistente:
|
0 |
update-initramfs -u |
Per effettuare i test riavviare il nodo e selezionare Memory Test nel grub prima che venga avviato Proxmox:
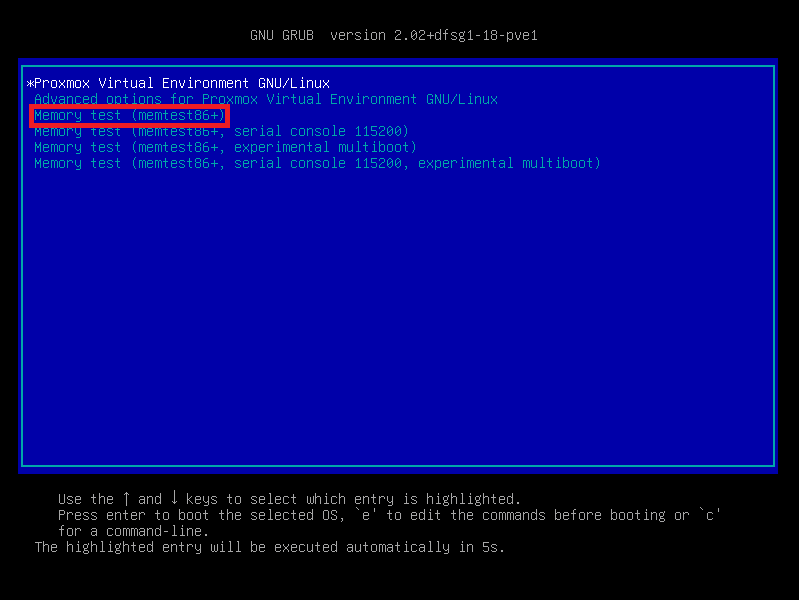
Se dovesse avviarsi con degli errori relativi alla firma invalida disabilitare momentaneamente il Secure Boot dal BIOS.
Se dovessero essere mostrati degli errori durante il test non è necessario farlo proseguire, rimuovere le RAM ed eseguire nuovemente il test, finché non si identifica quella difettosa.
Dopo aver sostituito la RAM difettosa, riavviare Proxmox e verificare se i servizi sono ancora falliti, se lo sono procedere alla rimozione dell’OSD e del monitor.
RIMUOVERE OSD
Identificare l’OSD con stato down con il comando:
|
0 |
ceph osd tree |
Dovremmo visualizare il seguente output:
|
0 1 2 3 4 5 6 7 |
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 5.45819 root default -10 1.81940 host pve01 2 nvme 1.81940 osd.2 up 1.00000 1.00000 -3 1.81940 host pve02s 0 nvme 1.81940 osd.0 up 1.00000 1.00000 -5 1.81940 host pve03 1 nvme 1.81940 osd.1 down 0 1.00000 |
Oppure dalla web UI di Proxmox:
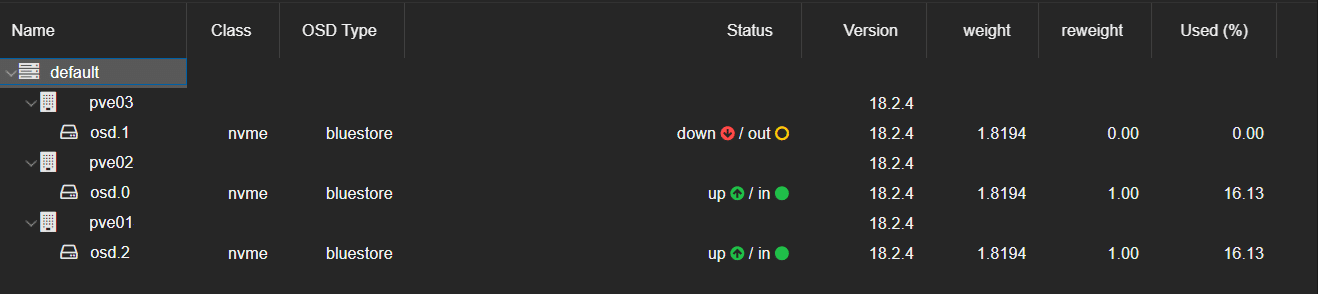
In questo caso l’OSD ha ID 1.
Procedere alla rimozione dell’OSD con i seguenti comandi: (sostituire 1 con l’ID dell’OSD da rimuovere)
|
0 1 2 |
ceph osd destroy 1 ceph osd purge 1 ceph auth del osd.1 |
Se si vuole rimuovere il nodo dalla Crush map, per esempio per reinstallarlo con un hostname diverso, è possibile eseguire il seguente comando (sostituire pve03 con il nome del nodo):
|
0 |
ceph osd crush remove pve03 |
RIMOZIONE DEL VOLUME CEPH
Tramite lsblk è possibile verificare il nome del volume Ceph:
|
0 1 2 |
root@pve03:~# lsblk nvme0n1 259:0 0 1.8T 0 disk └─ceph--a07c107b--639b--45ab--9ed9--78b74b76591a-osd--block--6ac55207--ec76--4365--b381--a34c7f783d1a 252:2 0 1.8T 0 lvm |
Procedere alla rimozione del volume (sostituire il path del volume Ceph con quello identificato tramite “lsblk”):
|
0 |
ceph-volume lvm zap --destroy /dev/ceph-a07c107b-639b-45ab-9ed9-78b74b76591a/osd-block-6ac55207-ec76-4365-b381-a34c7f783d1a |
Infine, è possiible rimuovere eventuali signatures del filesystem rimaste (sostituire il path con quello del disco che conteneva il volume Ceph appena rimosso):
|
0 |
wipefs -a /dev/nvme0n1 |
RIMOZIONE DEL MONITOR CEPH
È possibile rimuovere il monitor di Ceph dalla Web UI di Proxmox.
Navigare nella sezione Monitor di Ceph, selezionare il monitor da rimuovere e cliccare su Destroy:
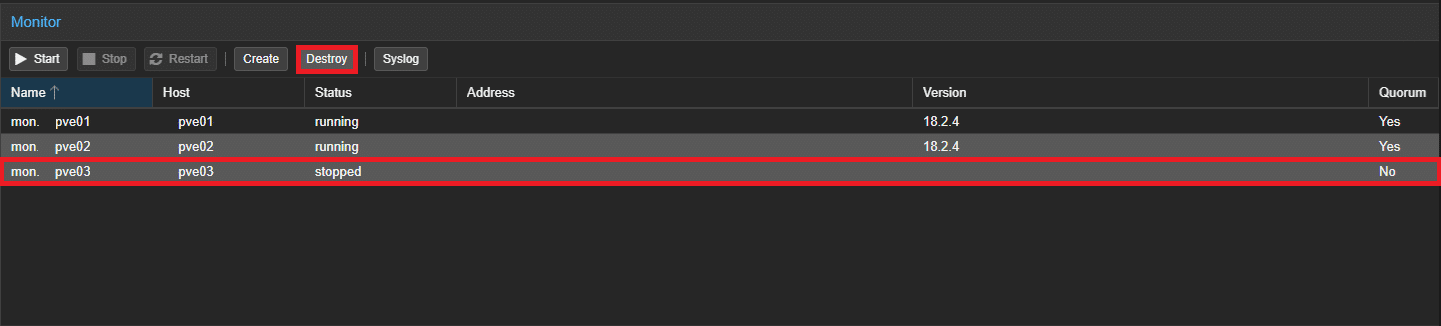
Infine confermare cliccando Yes:
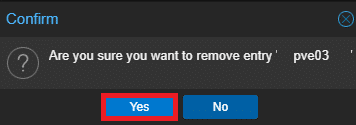
RIDURRE IL NUMERO DI REPLICHE
Se non si hanno nodi a sufficienza per mantenere il numero di repliche richiesto, è possibile ridurlo temporaneamente.
Navigare nella sezione Pools di Ceph, selezionare il Pool che si vuole modificare, cliccare su Edit e ridurre il numero di repliche:
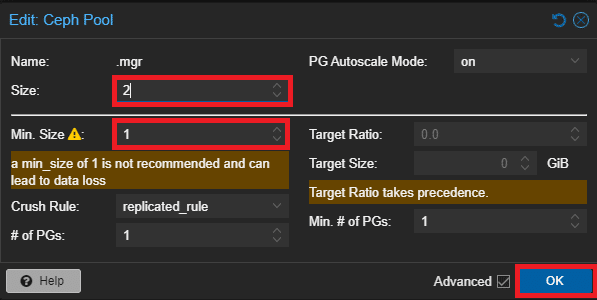
Ripetere l’operazione per tutti i Pools.
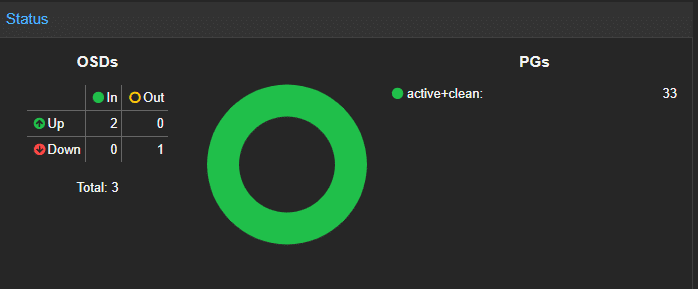
Dopo poco dovrebbe essere possibile visualizzare il cluster nello stato HEALTH_OK:
AGGIUNGERE IL MONITOR CEPH
Navigare nella sezione Monitor di Ceph e cliccare Create:
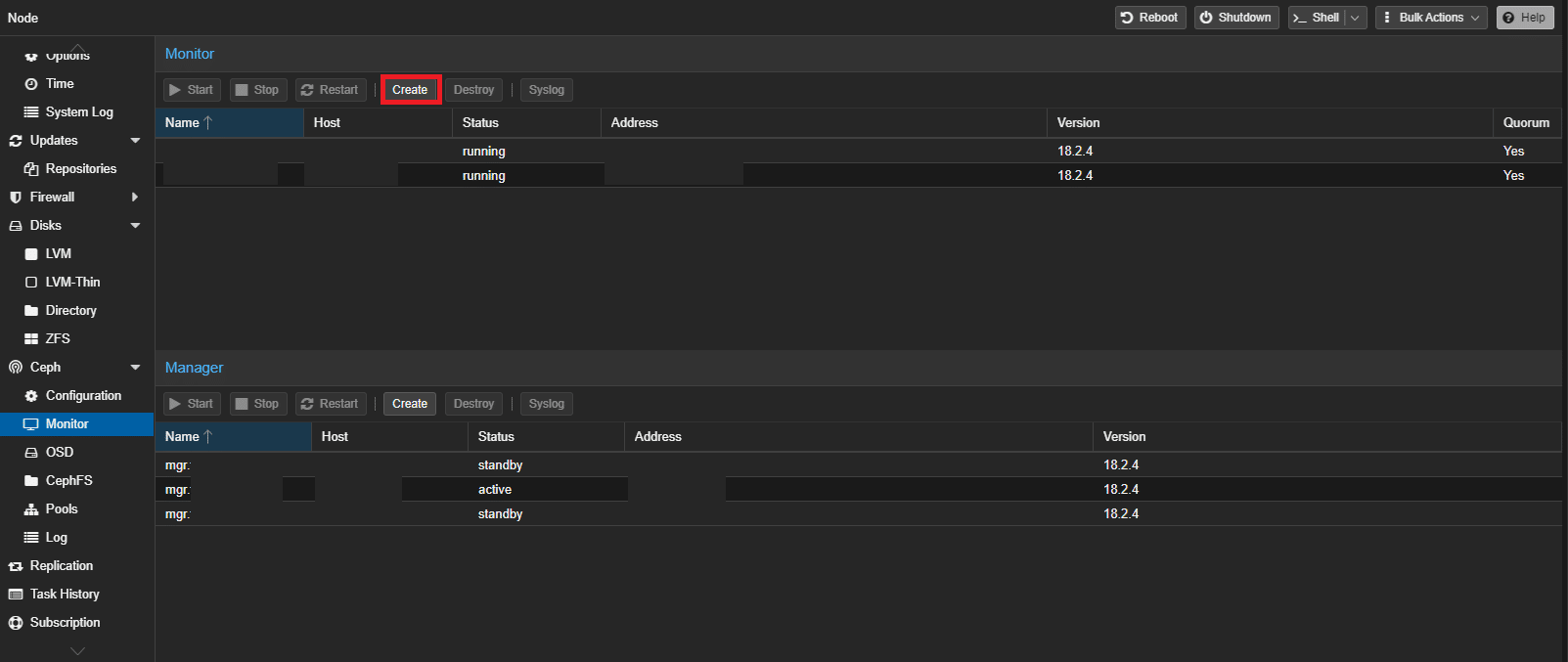
Selezionare l’host su cui creare il monitor e cliccare su Create:
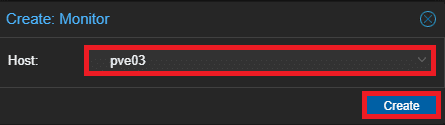
Verificare che il monitor appena creato sia attivo:
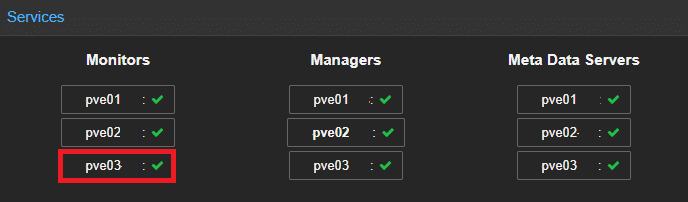
AGGIUNGERE OSD CEPH
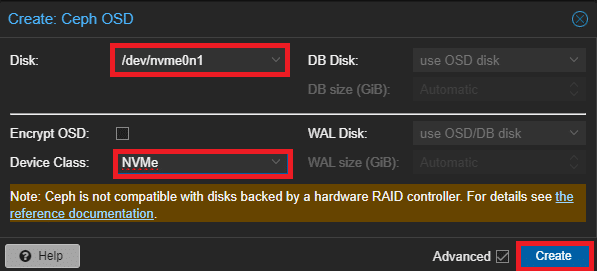
Selezionare il nodo su cui è presente il disco dell’OSD da creare, navigare nella sezione OSD di Ceph e cliccare su Create: OSD:

Selezionare il disco, il tipo di disco e cliccare su Create:
Se dovessero venir mostrati errori che affermano il monitor Ceph già esiste, rimuovere il suo IP dalla direttiva “mon_host” nella sezione [global] del file /etc/ceph/ceph.conf:
|
0 1 2 3 |
[global] ... mon_host = 10.10.110.11 10.10.110.12 ... |
Verificare che l’OSD appena creato sia attivo:

AUMENTARE IL NUMERO DI REPLICHE
Dopo aver ripristinato lo stato di salute del cluster Ceph è possibile aumentare il numero di repliche.
Per farlo tornare nella sezione Pools di Ceph, selezionare il Pool che si vuole modificare, cliccare su Edit e aumetare il numero di repliche:
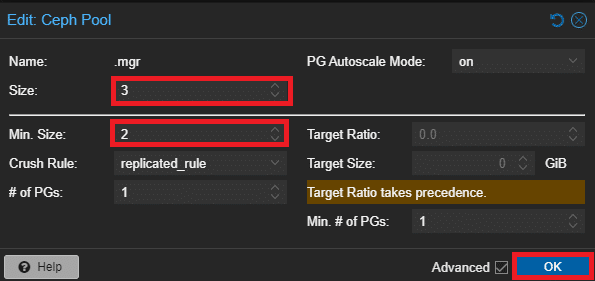
Ripetere l’operazione per tutti i Pools.
Dopo poco dovrebbe essere possibile visualizzare dalla Web UI di Proxmox lo stato di avanzamento del ribilanciamento di Ceph:
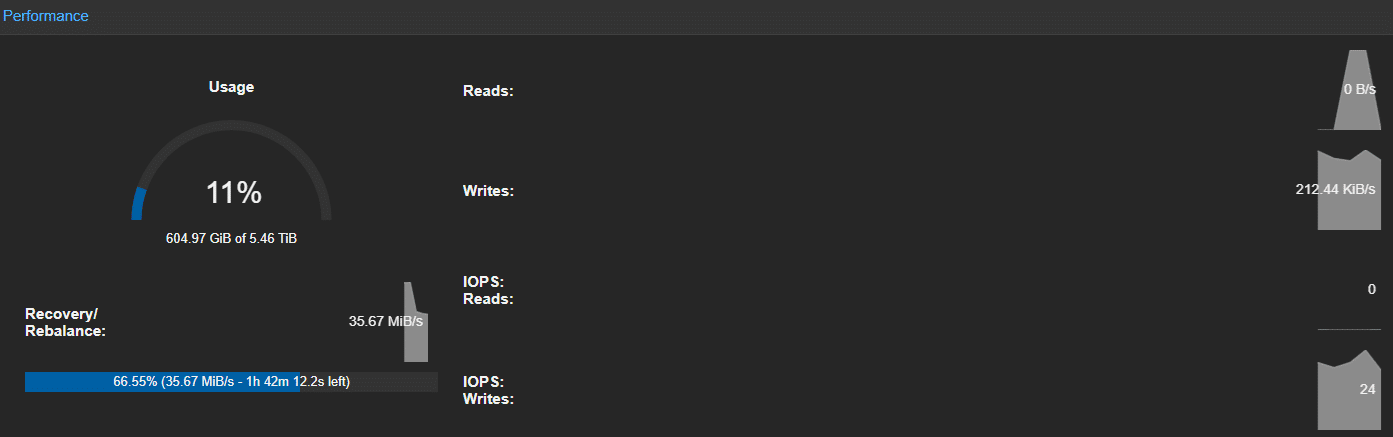
CORREGGERE PG INCONSISTENTI
Nel caso in cui si verificassero errori relativi a PG (placement groups) incosistenti è possibili identificarli dalla Web UI di Proxmox:
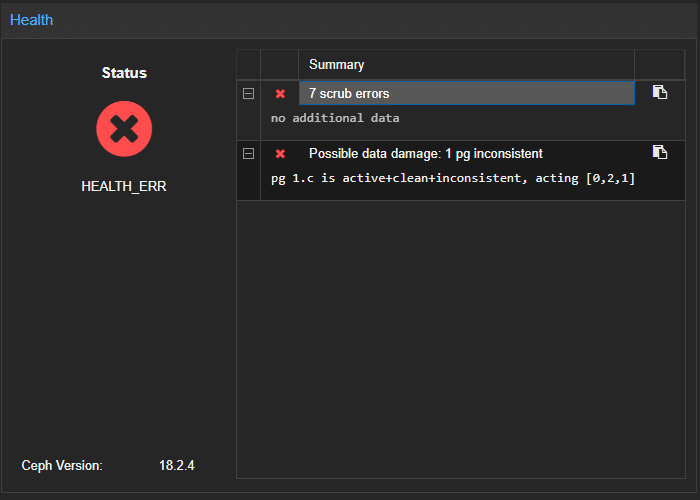
Identificare l’ID del PG danneggiato tramite il seguente comando:
|
0 1 2 3 4 |
root@pve03:~# ceph health detail HEALTH_ERR 7 scrub errors; Possible data damage: 1 pg inconsistent [ERR] OSD_SCRUB_ERRORS: 7 scrub errors [ERR] PG_DAMAGED: Possible data damage: 1 pg inconsistent pg 1.c is active+clean+inconsistent, acting [0,2,1] |
In questo caso l’ID è “1.c”.
Eseguire il seguente comando per riparare il placement group (sostituire “1.c” con l’ID del PG incosistente):
|
0 |
ceph pg repair 1.c |
Dopo non molto il cluster dovrebbe tornare nello stato HEALTH_OK.












0 commenti